
# Graph Generation Model
# Autoregressive Deep Graph Generators (DGGs):
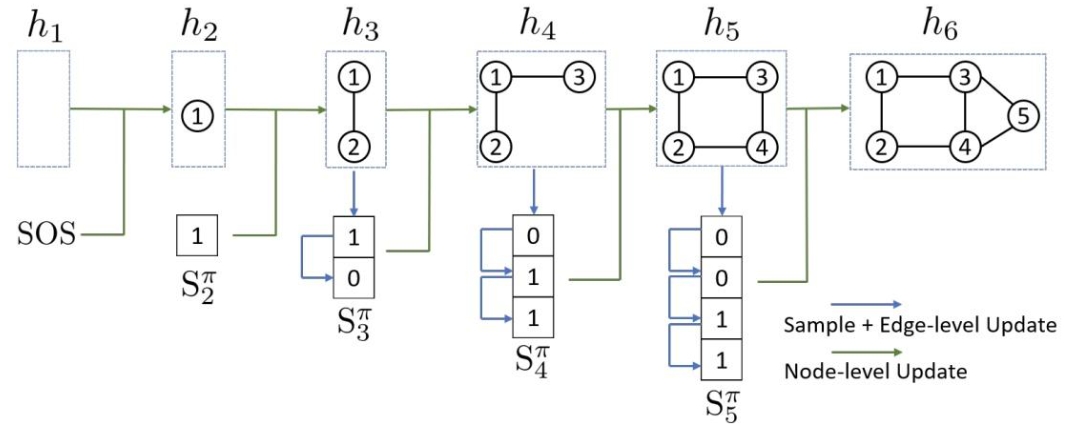
The core idea of autoregressive models for generative tasks is to simulate the dependencies between elements in sequential data. These models learn how each element in a sequence depends on its preceding elements to generate new data. In simpler terms, the model builds the sequence step by step, predicting the next element based on what has already been generated.
Using text generation as an example, an autoregressive model would initially receive a starting text sequence (like the beginning of a sentence) and then progressively generate subsequent words. At each step, the model considers the already generated words to predict the next most likely word. This process continues until a complete sentence is generated or a predetermined length is reached.
A key feature of these models is that they rely on all previously generated elements when generating each new element, enabling them to capture long-term dependencies within the sequence. A typical representative of autoregressive models is the Transformer model, which enhances the ability to capture such dependencies through self-attention mechanisms.
Autoregressive models are widely applied in natural language processing, music generation, image generation, and other fields. They are typically capable of generating coherent and somewhat creative content, but they also face issues with slow generation speed and potential repetitiveness.
- Node-by-Node Generators: These methods add a new node to the graph one at a time. For example, MolMP and MolRNN decide whether to append a new node to the graph, connect the last added node to previous ones, or terminate the process.
- Edge-by-Edge Generators: These methods generate a sequence of edges for each graph. For instance, GraphGen converts a graph into an ordered edge sequence and generates edges sequentially.
# Autoencoder-Based Deep Graph Generators:
Based on the autoencoder architecture, generative models fundamentally aim to learn a compact representation of data and then reconstruct it. The core idea revolves around two main components: the encoder and the decoder.
- Encoder: This is a neural network that takes an input (like an image or a sentence) and maps it to a lower-dimensional, abstract representation or encoding. This encoding simplifies the data, capturing its essential features.
- Decoder: This is another neural network that takes the encoded representation and reconstructs the original input. The goal is to generate data that is as close as possible to the original input.
The generative aspect comes into play when the encoder and decoder are trained to reconstruct data. Once trained, the model can generate new data by feeding random noise into the encoder, which then passes it through the decoder to produce a synthetic output that resembles the original data distribution.
This approach is particularly powerful for tasks like image generation, where the model can learn to create images that look realistic by training on a large dataset of real images. The latent space (the space of encoded representations) learned by the autoencoder can be explored to generate new, varied outputs.
In summary, autoencoder-based generative models learn to compress and reconstruct data, and by doing so, they learn to generate new content that fits the statistical patterns observed in the training data.
# Reinforcement Learning (RL)-Based Deep Graph Generators:
The core idea of generative models based on reinforcement learning is to use an agent to optimize its generation process to produce outputs that best match the desired goals. This agent learns to generate data by interacting with an environment.
- Agent: This is the main entity of the model, which tries to generate data and receives feedback on its performance.
- Environment: This is the context in which the agent generates data, such as the context of a language model in text generation.
- Actions: These are the choices the agent makes at each step of generating data, like selecting the next word or character.
- Rewards: When the agent generates data, it receives rewards based on how good its output is. Good results are rewarded, while poor results are penalized or receive negative rewards.
- Policy: This is the set of rules that the agent follows to choose actions based on its current state.
- Learning Process: Through trial and error, the agent learns which sequences of actions (policies) maximize cumulative rewards.
In reinforcement learning, the agent improves its policy by constantly trying to generate data and receiving rewards. Over time, the agent learns to generate data that increasingly aligns with the expectations of the target environment. This approach is widely applied in areas such as gaming, robotic control, and creative content generation.
These methods utilize reinforcement learning algorithms to induce desired properties in the generated graphs. For example, GCPN models graph formation as a Markov Decision Process to train an RL agent in a chemistry-aware environment.
# Flow-Based Deep Graph Generators:
The core idea of flow-based generative models is to simulate the generation process of data using probability distributions. These models construct a continuous, invertible transformation process to gradually add complexity to a simple data representation.
- Simple Random Variables: The model starts with a simple distribution that is easy to generate, such as a uniform or Gaussian distribution.
- Continuous Transformations: Through a series of invertible, parameterized transformation steps, the model gradually adds complexity, with each step depending on the result of the previous one.
- Parameterized Transformations: These transformation steps are typically implemented by neural networks, which can capture the complex structure of the data.
- Invertible Process: Because the transformations are invertible, the model can generate samples from the complex distribution by running these steps in reverse.
- Generating Samples: During the generation process, the model starts with a simple distribution and, through a series of transformation steps, ultimately produces the desired complex data samples.
Flow-based generative models can generate high-quality data because they directly model the underlying distribution of the data. This approach is applied in fields such as image generation, speech synthesis, and natural language processing, particularly when generating data with rich details and structure.
These methods combine normalizing flows with graph auto-encoders to generate graphs. For example, GNF develops a generative model of graphs by combining normalizing flows with a graph auto-encoder.